
英文腔調辨識之研究
摘要
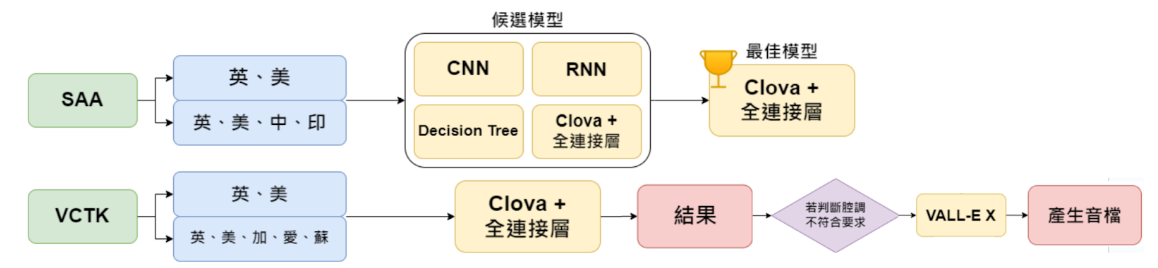
本研究建立 RNN、CNN、Decision tree 共三個機器學習模型,以及利用 Transfer Learning 將 Clova 模型配合全連接層使用,對 Speech Accent Archive(SAA)、VCTK 資料庫中不同腔調的英文音檔進行分類,並比較得出使用 Clova 之模型準確度最高。接著,我們透過上述腔調辨識模型以 VALLE-X 建立腔調合成模型,將不標準腔調轉換成為標準腔調,並輸出音檔。
研究目的
- 利用 SAA 資料庫訓練可分辨不同腔調的模型,並分成英式或美式。
- 沿用上述訓練結果,將分辨的類別增加為英式、美式、中式、印度式,以檢視各模型成效。
- 使用 VCTK 資料庫加以應用於上述兩項表現最佳模型並觀察結果。
- 若腔調辨識模型之分類結果不同於目標腔調,則從資料庫中選擇和原本的聲音相近之標準腔調音檔,進行語音合成。
研究過程與方法
研究成果與展望
- CNN、RNN、Decision tree 三種模型中,以 RNN 表現最佳。
- 以語者辨識的 Clova 模型自動提取特徵之方法,相較傳統 MFCC 表現更好。
- 目前我們已能夠將一段不標準的腔調,從資料庫中選擇聲音與原本最相近者,進行語音合成,產生發音較標準之音檔。
- 未來我們會混合兩資料庫之音檔做訓練,也會試著製作線上版的標準腔調生成工具,願在便利和應用層面多加發展。