
基於深度學習之背景噪音去除
摘要
本研究旨在利用深度學習訓練出可進行背景噪音去除之模型。我們主要利用英文、人聲背景噪音資料集 LibriSpeech 與中文、非人聲背景噪音資料集 TMHINT 進行模型訓練。本研究使用的是 Convolutional Recurrent Network(CRN)模型,並比較以 LibriSpeech、TMHINT 及 LibriSpeech 訓練後以 TMHINT 微調的三種訓練資料集之訓練結果。
研究目的
- 進行背景人聲與非人聲噪音去除
- 比較不同訓練資料集之訓練結果
研究過程與方法
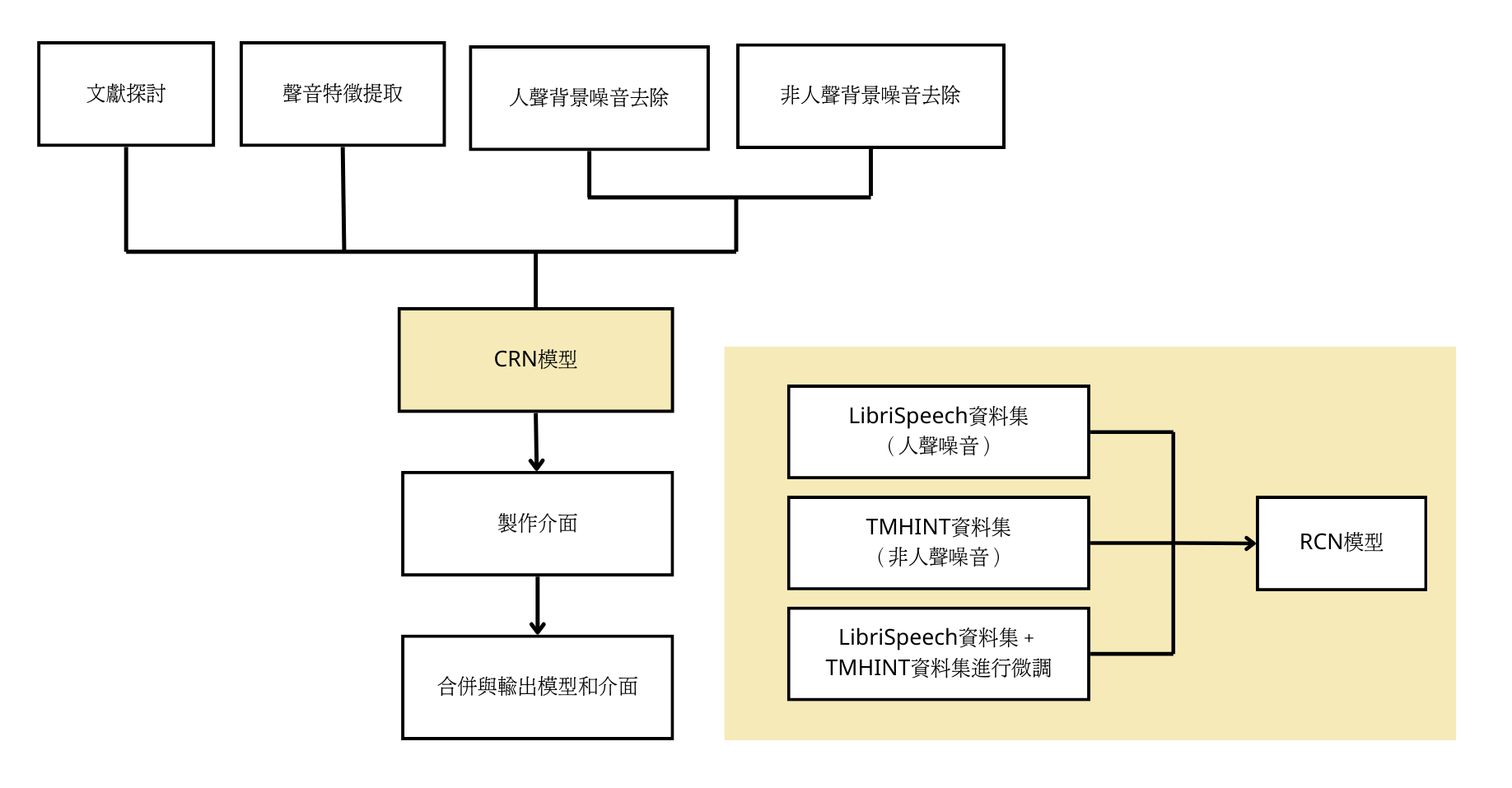
研究成果與展望
研究結果顯示,以 LibriSpeech 訓練的模型可以得到最好的結果:PESQ=1.36 和 STOI=0.78。其中訓練資料集的講者數量也會影響整體結果,講者數量越多,測試時的結果分數越高。另外,從經過微調後的模型結果可得知,訓練資料集的語言十分重要。直接使用中文訓練的模型和使用英文訓練後以中文微調的模型相比,直接使用中文的模型能在中文測試集中有更好的表現,英文亦是如此。
本研究初步設計一款利用訓練出的模型對音檔進行背景噪音去除的軟體,並希望未來能使用更大量、更多元的資料訓練模型,讓模型的準確度提高,以更好的進行背景噪音去除。
Back